014 - RT(F)M for the Peraire Experiment
Turns out, there is more to say on last week's experiments on the Peraire dataset! And I found out while I was working on a completely different dataset. Let me explain!
This morning, I helped my colleague train a Kraken transcription model for Greek manuscripts. They gave me the ground truth and I set and executed the training from the command line. It gave me an opportunity to try fine-tuning a model like CREMMA Medieval, in stead of only training from scratch. CREMMA Medieval was trained on manuscripts written in Latin, whereas the Greek manuscripts were written only, well, in Ancient Greek. I didn't want the resulting model to add Latin letters in the transcription when applied to other Greek documents, so I used Kraken's option to allow the model to forget previously learned characters and to force it to only remember the characters contained in the new training data. This option is called --resize (check the documentation here).
When I fine-tune a model, I usually follow Kraken's recommendations and keep both the previously learned characters and the new ones coming from the new set of ground truth. When this morning I checked what is the keyword to use to keep only the characters from the new dataset, I realized that I didn't correctly set the training on Peraire last week. I had set it to only keep the new characters!
Up until Kraken v. 4.3.10, --resize can take the keywords both or add. The ambiguity of these keywords has been discussed in the past, which is the reason why starting from Kraken v. 4.3.10, the keywords respectively become new or union.
Let's quote the manual:
There are two modes dealing with mismatching alphabets, add and both. add resizes the output layer and codec of the loaded model to include all characters in the new training set without removing any characters. both will make the resulting model an exact match with the new training set by both removing unused characters from the model and adding new ones.
I fell for this trap of ambiguity and used both instead of add, thinking both meant I was keep both character sets. (Again this is the very reason why the keywords were recently changed).
Side note: you should really read last week's post to fully understand the rest of this post!
At the end of my post last week, I wrote:
peraire_D on the other hand seems to lose it completely on the B series. This is most likely due to the fact that the contrast between the page and the "ink" is too low in the pencil-written series compared to the data used to train Manu McFrench and in the D series. peraire_D even loses 11 points of accuracy to Manu McFrench!
But how could I be sure that it was not actually due to the fact that the model had unlearned some precious characters?
The only way to know, I thought, was to re-train the models! I used this opportunity to also train the models from scratch because I was curious to see how much noise/improvement was brought by the base model.
I tried 4 types of models and, like last week, used CERberus 🐶🐶🐶 to measure the character error rates on the predictions made on the test sets:
- Models trained "from scratch"
- A model not trained on any data coming from the Peraire dataset (aka Manu McFrench)
- Models obtained from finetuning Manu McFrench using the add resize mode
- Models obtained from finetuning Manu McFrench using the both resize mode
For each model trained on the Peraire dataset, I used 3 compositions:
- the full dataset ("ALL")
- only data coming from the B series ("B")
- only data coming from the D series ("D")
I used the same composition system for the test sets.
Here are my results in the form of a table:
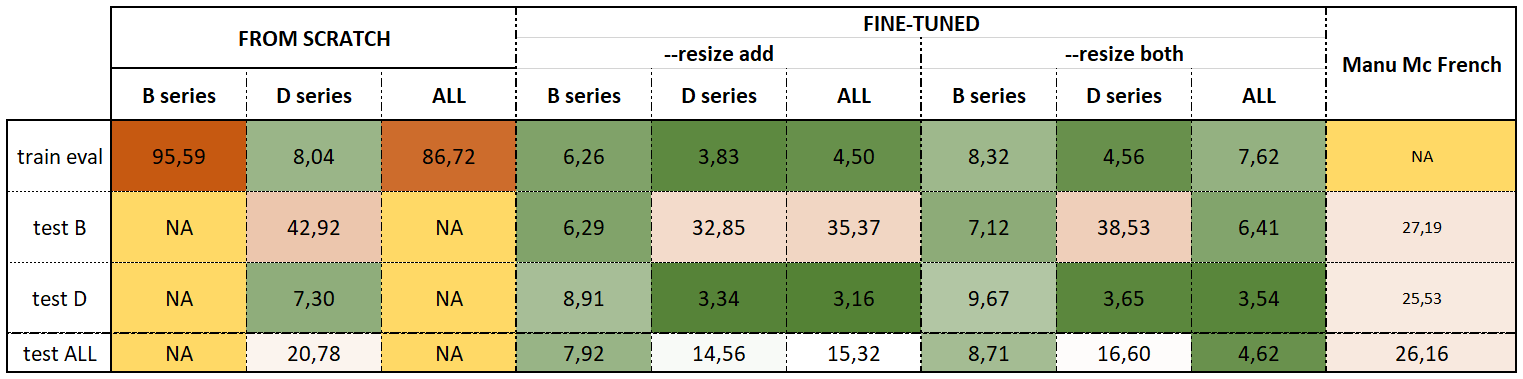
Fortunately, it seems that my previous interpretation is not fully contradicted by the results I obtain with this second series of training. Let's focus on two observations:
-
Whenever a model is trained only on the D series, and tested only on the B series, it appears to be completely incapable of predicting anything but gibberish, losing between 32 and 35 points of accuracy. It confirms that the aspect of the documents from the two series are too different. On the other hand, when the model is fine-tuned on the B series only, it maintains a fairly good accuracy when applied to the D series, whichever resize mode is used. I think it confirms that the B series is enough for the model to learn some sort of formal features from Peraire's handwriting, which the models can transfer to documents written with a different writing instrument.
-
What is very interesting is the difference between the models trained on the whole datasets and tested on the B series: when we use the both resize mode (meaning we only keep the characters from the new dataset), the model is very good. On the contrary, the performance of the model trained with the add resize mode (meaning we keep the output layer and the codec from the base model and add the new characters) is as bad as with a model trained only on the D series.
In my previous post, I wrote:
peraire_both is able to generalize from seeing both datasets and even benefits from seeing more data thanks to the D series, since it performs better on the B series compared to peraire_B.
However, in the light of my experiment with the resize option, I think this is not correct. Instead, it appears that resetting the output layer by using both (or new) on accident, allowed the model to better take into account the data from the B series (pencil). Contrary to what I observed last week, the model trained on the whole dataset but this time with the add resize mode (or union) doesn't benefit from seeing more data compared to the model trained only on the B series.
My understanding is that keeping the output layer from the base model with add (or union) probably drowns the specificity of the pencil-written documents into a base knowledge tailored to handle documents with a high contrast (like the ones in the D series and in Manu McFrench's training set). Or, to put it differently, when we use both (or new), more attention is given to the pencil written documents, meaning that the model actually gets better at handling this category of data.
I am extremely curious to see how I can investigate this further, or if any of you, readers, would understand these results differently!