
Objectifs du cours¶
🏆 Comprendre ce qu'est un document sur un ordinateur
🏆 Savoir différencier les catégories de fichiers et les standards et formats qui leur sont associés
🏆 Savoir différencier la mise en forme d'un fichier et sa structuration sémantique
🏆 Connaître théoriquement plusieurs modes d'organisation et de mise en forme d'un fichier textuel (XML, Markdown, LaTeX, ...)
🏆 Connaître théoriquement plusieurs modes de représentation de données organisées dans un fichier textuel (CSV, JSON)
🏆 Connaître les principaux standards XML et l'environnement technologique associé à ce standard
Plan du cours 1¶
- Cadrage sur la notion de "document numérique"
- Préambule sur la notion d'encodage numérique
- Encodage des données textuelles
- Encodage des images numériques
- Encodage des autres fichiers multimédia
- Acquisition de données textuelles
- Bonus : les expressions régulières
Autour de la notion de "Document numérique"¶
Point terminologique¶
Numérique :¶
- fait référence au domaine informatique (automatique + information)
- renvoie à la nature matériel du document : "électronique"
Electronique :¶
- un composant matériel électronique ne répond qu'en terme de "on/off" (courant électrique)
- représentation binaire : On = 1, Off = 0
Un
document physiqueexiste dans le monde matériel.Un
document numériqueexiste sur un plan matériel (hardware) et immatériel (software)- contenu encodé sous la forme de suites de 0 et de 1
- matérialisé virtuellement sous la forme d'un
fichier
Un
fichier numériqueenregistre des données constituant ou non un document.dématérialisévs.nativement numérique
Intermédiaire(s)¶
"une large partie des oeuvres de la communication contemporaine ne se laisse saisir que par la médiation d'un appareillage technique plus ou moins complexe. Il s'agit de dispositifs de lecture sans lesquels l'accès au message est impossible" (D. Cotte, Le concept de « document numérique », 2004)
- Appareillage technique multiple :
- décodage des éléments electroniques vers des informations numériques
- interprétation du format d'enregistrement
- affichage
Gestionnaires de fichiers¶

Paradigmes apparus dans les années 1970 :
- En même temps que les
interfaces graphiques - Représentation des données numériques en
fichiers,dossiers - Organisation autour d'un
Bureauet selon unearborescence
Cela ne correspond pas à la manière dont les données sont stockées sur un disque dur, mais facilite la représentation des informations pour les humains.
- Pour comprendre comment fonctionne un disque dur : https://www.youtube.com/watch?v=bMSXQhra6hY
Structure d'un fichier numérique¶
Propriétés élémentaires :
- un
nom - un
formatindiqué par sonextension - une
taille(oupoids)
- un
Des métadonnées (informations sur le contexte et les modalités de création)
datede création, de modification- identité des
créateur-rice(s) logicielde création- etc...
Focus sur le format¶
C'est :
- une norme pour la représentation des données (texte, son, image, etc)
- une sorte de « gabarit » indiquant :
- les informations nécessaires à la constitution du fichier
- dans quel ordre les enregistrer ou à quel endroit dans le fichier
Exemple du format ZIP¶
- formalisation sous la forme d'une norme ISO/IEC (21320-1) en 2015
- spécifications techniques pour la version 6.3.3 publiées en 2012 : "APPNOTE"
ZIP : que dit la norme ISO 21320-A¶
Introduction :
"It is often useful to combine multiple digital resources into a single digital resource to make them easier to store and process. The combined digital resource may also use data compression to minimize the space needed for storage. [...] The technology defined by the Zip Application Note has been in wide use in ICT industries for over twenty years, and the specification has been freely available for much of that time."
Requirements
"A digital resource is conformant to this part of ISO/IEC 21320 when it is in accord with the provisions of this part of ISO/IEC 21320. Such a digital resource is a document container file."
Renvoi aux specifications techniques de 2012
ZIP : que disent les spécifications techniques¶
4.1 What is a ZIP file
----------------------
[...]
4.1.2 ZIP files SHOULD contain at least one file and MAY contain multiple files.
4.1.3 Data compression MAY be used to reduce the size of files placed into a ZIP file, but is not required.
[...]
4.2 ZIP Metadata
----------------
4.2.1 ZIP files are identified by metadata consisting of defined record types containing the storage information necessary for maintaining the files placed into a ZIP file. Each record type MUST be identified using a header signature that identifies the record type. Signature values begin with the two byte constant marker of 0x4b50, representing the characters "PK".ZIP : que disent les spécifications techniques¶
Organisation des informations à l'intérieur du fichier :
4.3.7 Local file header:
local file header signature 4 bytes (0x04034b50)
version needed to extract 2 bytes
general purpose bit flag 2 bytes
compression method 2 bytes
last mod file time 2 bytes
last mod file date 2 bytes
crc-32 4 bytes
compressed size 4 bytes
uncompressed size 4 bytes
file name length 2 bytes
extra field length 2 bytes
file name (variable size)
extra field (variable size)Différentes catégories de formats¶
Format propriétaire¶
- spécifications techniques sont la propriété (intellectuelle) d'une entité privée
souvent brevetées, donc utilisation soumise à des limitations
opaque:- pas de diffusion
- le fichier ne peut être traité que par le logiciel (propriétaire) qui le produit
publié:- quand même soumis aux limitations du brevet
- le fichier peut être traité par d'autres logociels
- risque de perte d'accès aux specs
Format libre/ouvert¶
- spécifications techniques publiques et sans restriction d'accès
- le fichier peut être traité par n'importe quel logiciel développé pour le supporter
- pas toujours standardisé
Standard de fait¶
- spécifications techniques existent, sont publiques et adoptées très largement
- mais n'ont pas (encore) fait l'objet d'une standardisation officielle
Norme¶
- spécifications techniques ont fait l'objet d'une standardisation officielle
- exemples d'organisation de normalisation : ISO, AFNOR, W3C
Attention, en anglais « standard » signifie « norme ».
Typologie de fichiers numériques¶
L'extension d'un fichier
- correspond à des normes (potentiellement infinies)
- nous donne une information sur la nature de son contenu
- indique à la machine comment le traiter
- permet aux logiciels de trier les fichiers compatibles
Fichier textuel :
- le destinaire peut être l'ordinateur (programme), un logiciel (page web), ou encore un humain
- ex :
.txt,.csv,.html,.py
Fichier de média :
- image :
.png,.jpeg,.gif - video :
.mp4,.avi,.mov - audio :
.mp3,.wav,.wma
- image :
Fichier complexe ou Fichier multimédia :
- fichiers complexes mélangeant plusieurs types de données (textuelles / non-textuelles)
- généralement le résultat de la compression de plusieurs fichiers numériques simples
- ex:
.docx,.odt,.pdf
Fichier exécutable :
- peuvent être exécutés par un programme pour réaliser une action
.exe,.sh,.app, ...
Fichier compressé ou Document Container File :
- regroupent plusieurs fichiers en un seul
- peuvent être décompressé à l'aide d'un logiciel
- peuvent réduire la taille globale du lot de fichier
- ex :
.zip,.tar,.rar
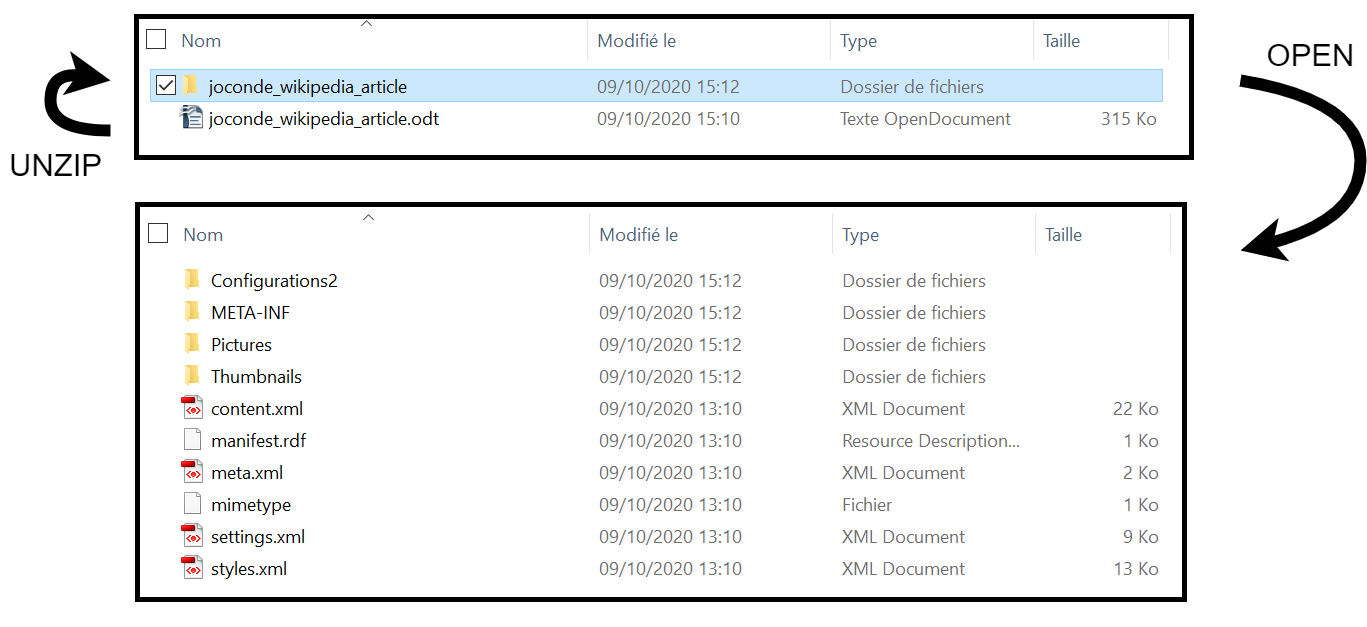
Décompression d'un document complexe¶
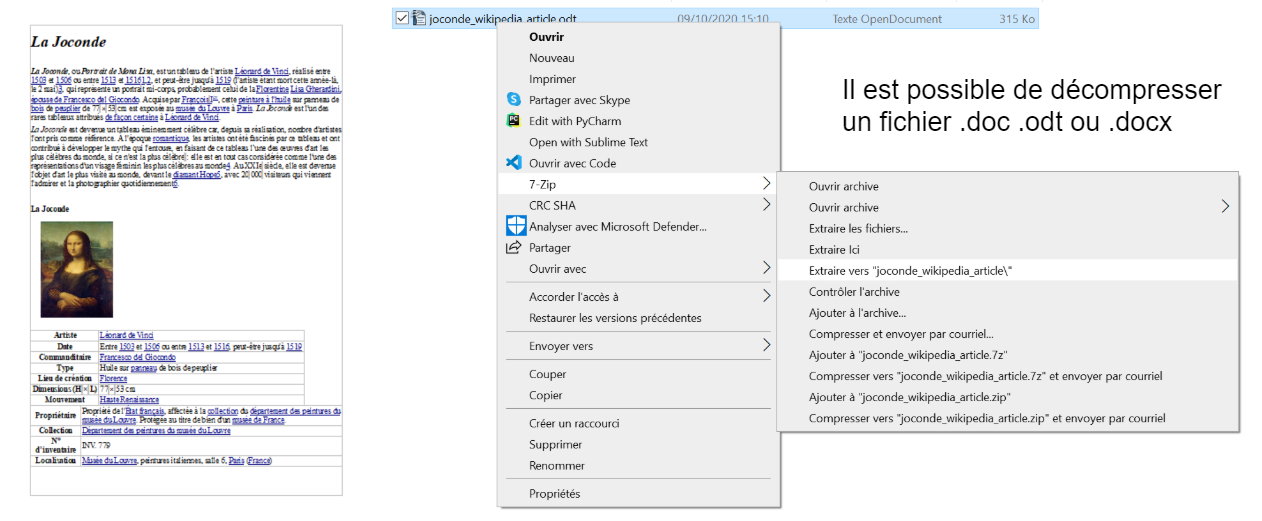
Décompression d'un document complexe¶
Documents numériques : récapitulatif¶
- plusieurs couches d'appareillage technique sont nécessaires
- un document numérique est un fichier, mais un fichier n'est pas forcément un document
- le format définit un gabarit public ou non, libre ou non, pour structurer l'information
- le statut d'un format dépend en grande partie du statut des spécifications techniques
- il existe une grande variété de types de fichiers, indiqué par leur extension
- certains fichiers sont des combinaison de plusieurs fichiers
Des questions ?¶
Encodage numérique¶
💾 L'encodage = transformation de données d'un format à un autre
💾 Le degré zéro = transformation de données en valeurs binaires (on/off). On représente ces états par un 1 ou un 0.
- un
bitest une instance de 0 ou de 1 - un
train de bits(oubyte) est un groupe composé d'une suite de bits - un
octetest un groupe de 8 bits
💾 Un fichier de 100 octets est + riche qu'un fichier de 10 octets
💾 La taille d'un fichier numérique = nombre d'instances de 0 et de 1 nécessaires à sa représentation
Mémoire¶
La taille d'un disque dur définit le nombre de bits disponibles pour encoder des informations simultanément.
Par exemple, un disque dur de 50 Go de mémoire :
- est égal à 50 000 000 000 octets (cinquante milliards)
- est égal à 400 000 000 000 bits (quatre cents milliards)
La taille d'un fichier définit le nombre de bits nécessaire à son encodage.
Par exemple, un fichier d'une taille de 30 Ko :
- nécessite 30 x 1 000 x 8 bits
- contient donc un total de 160 000 instances de 1 ou 0
Tout document conservé sur un ordinateur est constitué d'une série de 0 et de 1¶
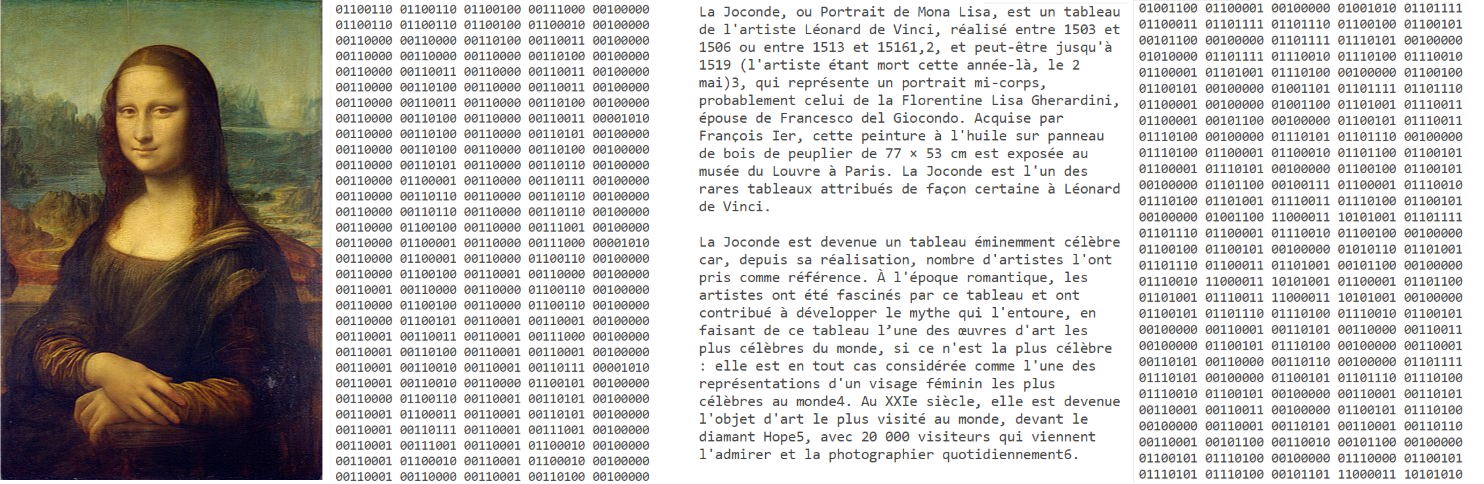
Comment passe-t-on d'une suite de 0 et de 1 à un texte ou une image sans se tromper dans l'interprétation ?
➡️ Grâce aux normes d'encodage et aux formats !
Normes d'encodage¶
🗝️ Les normes d'encodages = clefs d'encodage/décodage pour passer d'une forme intelligible pour les humains à une forme lisible par la machine
🗝️ En fonction du type de fichier encodé (texte, image, vidéo, etc.), il existe différents paysages de normes et de modes de représentation
🗝️ On en passe une partie en revue dans la suite du cours
Encodage des données textuelles¶
🅰️ Un document numérique textuel contient du texte (caractères alphanumériques et de symboles)
🅰️ La norme d'encodage d'un texte == une table de correspondance entre un groupe de bits et un caractère alphanumérique ou un symbole
🅰️ La norme d'encodage définit donc la liste des caractères disponibles (character set)
🅰️ En fonction de la norme, la représentation d'un caractère peut s'étendre sur un ou plusieurs octets
🅰️ Les normes les plus connues pour des textes en français sont :
ASCII(1963)ISO 8859-1(1986)UTF-8(1996)
ASCII¶
🅰️ American Standard Code for Information Interchange
🅰️ Chaque caractère est représenté par 7 bits empaquetés dans 1 octet
🅰️ Le jeu de caractères est composé de 95 éléments (pas de caractères accentués) :
!"#$%&'()*+,-./
0123456789:;<=>?
@ABCDEFGHIJKLMNO
PQRSTUVWXYZ[\]^_
`abcdefghijklmno
pqrstuvwxyz{|}~🅰️ Exemple : A = 01000001
ISO 8859-1¶
🅰️ Elle est souvent appelée Latin1 mais aussi Western Europe
🅰️ Chaque caractère est représenté par 8 bits
🅰️ ISO 8859-1 est rétrocompatible avec ASCII. Le jeu de caractères est composé de 191 éléments : les 95 caractères de la norme ASCII + des symboles et des caractères accentués :
!"#$%&'()*+,-./ ¡¢£¤¥¦§¨©ª«¬-®¯
0123456789:;<=>? °±²³´µ¶·¸¹º»¼½¾¿
@ABCDEFGHIJKLMNO ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏ
PQRSTUVWXYZ[\]^_ ÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞß
`abcdefghijklmno àáâãäåæçèéêëìíîï
pqrstuvwxyz{|}~ ðñòóôõö÷øùúûüýþÿ🅰️ Exemple: é = 11101001
UTF-8¶
🅰️ Universal Character Set Transformation Format + base d'encodage (8, 16, 32, ...)
🅰️ En fonction de la base d'encodage, un caractère peut être représenté par 1, 2, 3 ou 4 octets.
🅰️ UTF est rétrocompatible avec ASCII, mais pas avec ISO 8859-1. Il s'inscrit dans le cadre établi par Unicode qui vise à faciliter l'échange de textes numériques en assurant leur compatibilité.
🅰️ Unicode définit plus de 137 000 caractères, issus de multiples alphabets, et prévoit aussi des symboles comme les emojis.
🅰️ Exemple : 🤓 = 11110000 10011111 10100100 10010011
Mauvais encodage/décodage¶
Si on n'utilise pas la bonne clef d'encodage ou de décodage d'un texte, on risque d'obtenir un texte partiellement ou entièrement illisible.
UTF-8 ouvert avec 8859-1 (Latin 1)
La Joconde, ou Portrait de Mona Lisa, est un tableau de l'artiste Léonard de Vinci, réalisé entre 1503 et 1506 ou entre 1513 et 15161,2, et peut-être jusqu'à 1519 (l'artiste étant mort cette année-là , le 2 mai)3, qui représente un portrait mi-corps, probablement celui de la Florentine Lisa Gherardini, épouse de Francesco del Giocondo. Acquise par François Ier, cette peinture à l'huile sur panneau de bois de peuplier de 77 à 53 cm est exposée au musée du Louvre à Paris. La Joconde est l'un des rares tableaux attribués de façon certaine à Léonard de Vinci.UTF-8 ouvert avec ISO 8859-5 (Cyrillic)
La Joconde, ou Portrait de Mona Lisa, est un tableau de l'artiste LУЉonard de Vinci, rУЉalisУЉ entre 1503 et 1506 ou entre 1513 et 15161,2, et peut-УЊtre jusqu'У 1519 (l'artiste УЉtant mort cette annУЉe-lУ , le 2 mai)3, qui reprУЉsente un portrait mi-corps, probablement celui de la Florentine Lisa Gherardini, УЉpouse de Francesco del Giocondo. Acquise par FranУЇois Ier, cette peinture У l'huile sur panneau de bois de peuplier de 77 У 53 cm est exposУЉe au musУЉe du Louvre У Paris. La Joconde est l'un des rares tableaux attribuУЉs de faУЇon certaine У LУЉonard de Vinci.UTF est désormais la norme¶
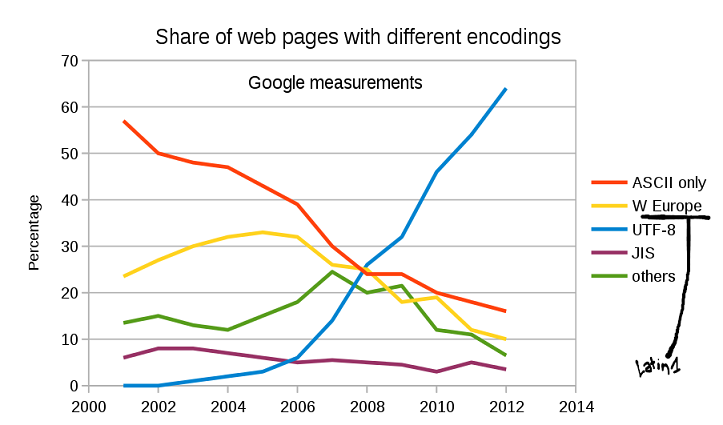
D'après W3Techs, 97,8% des pages web qui déclarent un encodage suivent UTF-8 aujourd'hui.
(source du graphique: Wikimedia)
Texte brut, texte enrichi¶
Un fichier de texte peut contenir des indications de mise en forme
texte brut(ouplain text) == un texte dépourvu d'information de mise en forme, qui se limite à l'affichage de la traduction des données binaires en caractères alphanumériques et symbolestexte enrichi(ourich text) == un texte qui comporte des éléments de mise en forme, qu'ils soient ou non affichés dans l'interface graphiqueWYSIWYG(What You See Is What You Get) == un éditeur de texte quie présente un texte enrichi avec sa mise en forme, de manière simultanéeWYSIWYM(What You See Is What You Mean) == un éditeur de texte qui présente le texte et ses informations de mise en forme dans les interpréter
🔤 les informations de mise en forme sont des annotations qui sont formées selon plusieurs standards ou normes.
🔤 parser un document == le traiter de manière à afficher la mise en forme
- pas de mise en forme :
<gras>du texte</gras> - mise en forme : du texte
🔤 les normes et standards encadrant la manière de former les annotations sont étroitement liées au format du document et au standard qu'il suit.
🔤 L'extension d'un fichier texte indique à l'utilisateur et à l'ordinateur quel est son format, c'est-à-dire :
- comment sont organisées les informations relatives au fichiers et les métadonnées
- avec quel logiciel l'ouvrir
- s'il contient ou non des informations de mise en page qu'il faut interpréter
🔤 On peut classer les fichiers en 2 catégories en fonction de leurs extensions :
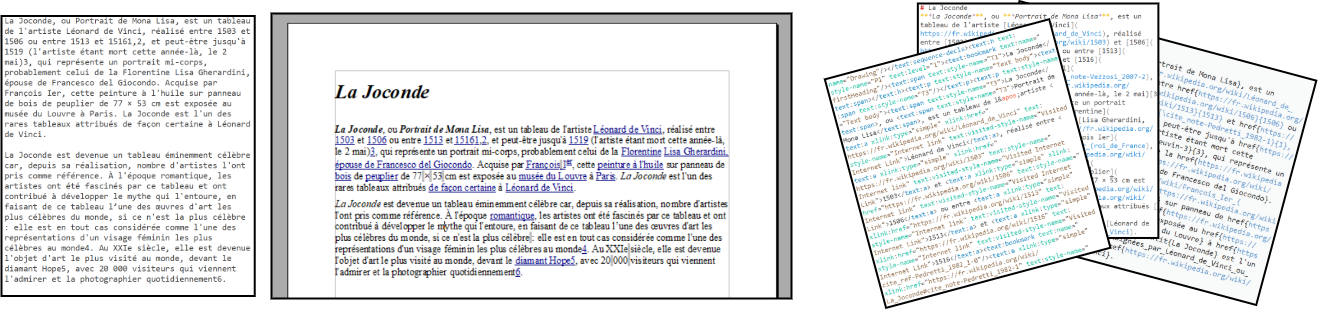
Exemple (de gauche à droite) : Texte brut -- texte enrichi interprété dans un éditeur de texte -- texte annoté en XML | en Markdown | en LaTeX affiché en plain text avec coloration syntaxique
Des questions ?¶
Encodage des images numériques¶
📷 Il existe 2 grandes catégories d'images numériques :
les
images matricielles;les
images vectorielles.

Images matricielles¶
📷 Les images matricielles (ou bitmap) sont des tableaux de points à 2 dimensions (hauteur, largeur)
📷 La définition d'une image indique les dimensions de sa matrice. Une image de dimensions "32 x 21" est donc un tableau de 32 colonnes (largeur) et 21 lignes (hauteur). L'image est représentée par 672 cases (ou pixels)
📷 Les pixels ont des propriétés (coordonnées, couleur)
📷 La résolution d'une image indique la taille de l'image dans dimensions matérielles. L'unité de mesure de la résolution dépend de l'unité de mesure matérielle : DPI (dot per inch) -> indique le nombre de pixels utilisé pour représenter 1 pouce (2,54 cm)
📷 La taille d'un fichier image ne dépend pas seulement du nombre de pixels mais aussi de la quantité d'informations contenues dans un pixel
Images matricielles et encodage de la couleur¶
L'encodage de la couleur dans les systèmes informatiques pourrait faire l'objet d'un cours à part entière.
🌈 Les principaux modes de représentation d'une image colorée (ou non) sont :
- le
mode binaire(noir ou blanc), - le
niveau de gris(intensité du noir entre 0 et 255*), - le
mode RGB(synthèse de trois couches monochromes contenant des valeurs d'intensité situées entre 0 et 255*).
🌈 Une image en mode RGB est donc composée de l'assemblage de 3 matrices.
* 0-255 quand la valeur est enregistrée sur 1 octet.
Schématisation du fonctionnement des modes binaires, niveaux de gris et RGB¶
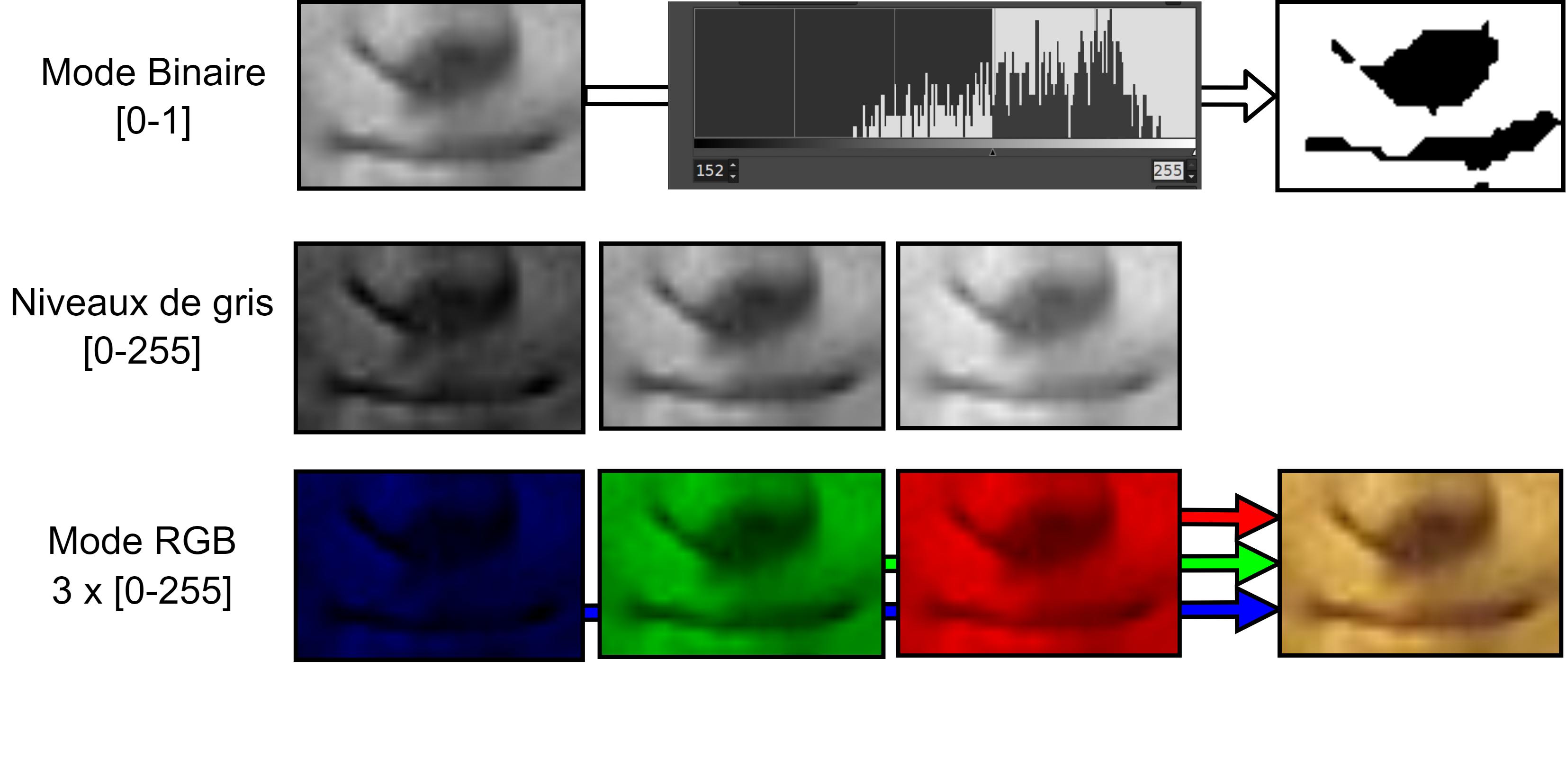
🌈 Un pixel contient la valeur d'intensité des points situés aux mêmes coordonnées sur chaque couche de couleur.

Le poids des images¶
⚖️ Le poids d'une image matricielle dépend en partie de la définition de l'image (nombre de pixels) et du mode de gestion des couleurs (nombre de couches de couleur)

Le poids des formats¶
⚖️ Le poids d'une image matricielle dépend aussi du format utilisé pour sa sauvegarde
⚖️ Formats compresseés : réduire la taille d'une image en simplifiant les informations selon 2 principes:
- certains éléments se répètent dans une image, on a donc intérêt à les représenter avec des raccourcis (à l'échelle des octets)
- on peut compter sur le cerveau humain pour compléter une partie des informations, on peut donc dégrader les informations non essentielles
⚖️ Certains formats audio et vidéo compressent les données selon les mêmes principes (ex: ondes sonores ou spectre de couleur non perçues par l'oreille ou l'oeil humain).
⚖️ Le taux de perte acceptable suite à la compression d'un fichier dépend de l'usage que l'on souhaite en faire (Ex : miniature ou impression grand format ?)

Images vectorielles¶
🧬 Une image vectorielle est décrite/contenue dans un fichier TEXTE
🧬 Des objets simples (segments, polygones, courbes de Béziers) et des propriétés (coordonnées, couleur de contour ou de remplissage, angle de rotation)
🧬 On peut modifier individuellement chacun de ces objets sans affecter l'ensemble
🧬 On peut animer une image vectorielle car les attributs d'un objet vectoriel peuvent être affectés par une variable de temps
🧬 Une image vectorielle n'a pas de résolution : elle est définie uniquement si l'on transforme l'image vectorielle en image matricielle
🧬 Le format d'images vectorielles le plus commun est SVG (Scalable Vector Graphics) : soit du XML
🧬 On peut ouvrir une image vectorielle avec un éditeur d'image (comme Illustrator ou Inkscape) ou avec un éditeur de texte ou un navigateur
Une image dans un fichier texte¶
On peut ouvrir une image vectorielle avec un éditeur de texte ou un éditeur d'image, on ne peut ouvrir une image matricielle qu'avec un éditeur d'image

Démo manipulation de fichier d'image véctorielle
Quelques liens pour mieux comprendre les fichiers audio, vidéo et PDF¶
Encodage du son et de la video¶
- 📽️ Digital Audio Explained - Samplerate and Bitdepth ( wickiemedia) : https://www.youtube.com/watch?v=BNVVq-iVPy8
- 📽️ How Digital Audio Works (Computerphile) : https://www.youtube.com/watch?v=1RIA9U5oXro
- 📽️ Digital Audio Compression (Computerphile) : https://www.youtube.com/watch?v=KGZ0een8vSE
- 📽️ The Very Basics of Digital Video ( FlikliTV) : https://www.youtube.com/watch?v=-1s-SuUQYs4
- 📽️ Video Formats, Codecs and Containers (Explained) (Qencode) : https://www.youtube.com/watch?v=XvoW-bwIeyY
- 📽️ Explaining Digital Video: Formats, Codecs & Containers (ExplainingComputers): https://www.youtube.com/watch?v=-4NXxY4maYc
Structure et contenu des PDFs¶
📽️ PDFScripting, What is a PDF (2017)
À partir de maintenant, on se concentre sur le cas données textuelles¶
Acquisition de données textuelles¶
Quelques méthodes d'acquisition de données textuelles¶
saisie manuelle ou génération automatique ;
récupération de données textuelles enregistrées dans une base de données ;
web scrapping ou extraction de contenus web (cf. DNH04) ;
transcription d'un fichier multimédia par l'analyse et l'interprétation de son contenu ;
Du fichier multimédia au fichier texte¶
passe par l'analyse de signaux ou l'analyse des contenus
grâce à une approche symbolique fondée sur des règles ou grâce à l'apprentissage automatique (machine learning)
En fonction du contenu multimédia, il y a plusieurs domaines :
reconnaissance vocale automatique (
speech to text)reconnaissance automatique d'écriture (
optical character recognition)génération de texte décrivant le contenu (
automatic image/video/sound annotation)transformation du texte en un autre texte (
text simplification), ce qui s'apparente à de la traduction
La reconnaissance automatique de caractères¶
- écritures imprimées : peu voire pas de variation dans la forme des lettres (fonte) et chaque lettre est distincte des autres

- écritures manuscrite : beaucoup de variations dans la forme des lettres, difficulté à dinstinguer certaines lettres, parfois des symboles (ou graphème) non standards
On parle d'OCR (Optical Character Recognition) pour l'imprimé ou d'HTR (Handwritten Text Recognition) pour les manuscrits
Etapes essentielles de la transcription automatique¶
Acquisition des images (numérisation avec un cahier des charges adapté (cadrage, résolution, etc.)) ;
(opt) Pré-traitement des images (cadrage, réduction du bruit, parfois binarisation) ;
Détection du texte sur l'image (segmentation) ;
Détection de la mise en page (Layout Analysis) et de l'ordre des lignes ;
Reconnaissance du texte (lettre par lettre, mot par mot ou même paragraphe par paragraphe, en fonction du logiciel) ;
(opt) Post-taitement des données textuelles (correction des erreurs de transcription, annotation du texte, etc.).

Aller plus loin sur la gestion d'un projet de transcription automatique¶
📽️ Alix Chagué, "Comment faire lire des gribouillis à mon ordinateur ?", tuto@mate (11 mars 2021)
➡️ https://mate-shs.cnrs.fr/actions/tutomate/tuto31-lire-des-gribouillis-chague/
Dématérialisation et transcription automatique¶
Certaines campagnes de dématérialisation allient numérisation et transcription (automatique)
Une campagne de transcription peut être mise en place de plusieurs manières :
- avec un logiciel propriétaire et/ou payant (ex: FineReader d'ABBYY, Transkribus )
- avec un logiciel libre et ouvert (ex: Tesseract, eScriptorium )
- par le biais d'un prestataire, qui prend en charge le post-traitement (cf. liste de prestataires de numérisation )
- accompagnée de *crowdsourcing** pour le post-traitement (ex : Transcribe Bentham )
* Attention : le crowdsourcing peut sembler une solution facile, mais cela demande beaucoup d'organisation et une gros investissement.
Dématérialisation et transcription automatique¶
On ne devrait pas faire de transcription automatique sans cahier des charges :
- fixer les pratiques de transcription souhaitées
- fixer le seuil d'erreur minimal accepté
- expliciter les post-traitements nécessaires
- expliciter les formats cibles
Quelques logiciels de transcription supplémentaires¶
- Logiciels de transcription (imprimé et/ou manuscrit) :
- Tesseract
- CitLab (via Transkribus)
- Kraken
- FineReader
- OCRopus
- Plateformes gérant l'ensemble du workflow :
- OCR4All
- eScriptorium
- Transkribus

🕵️ 1 syntaxe pour formuler des recherches (et des remplacements) dans un texte avec beaucoup de souplesse
🕵️ Aussi appelées REGEX (regular expression) ou de "recherche par motif"
🕵️ En principe disponibles dans presque tous les éditeurs de texte, moyennant activation
😔 Dans Microsoft Word les REGEX existent, mais depuis la version 2016, l'option s'appelle caractères génériques et la syntaxe diffère de la syntaxe universelle, même si le principe reste le même. ➡️ doc
Les REGEX sont utiles pour trouver rapidement des informations dans un texte même lorsque celles-ci varient :
Rercher des dates :
- Au lieu de chercher "1900", "1901", "1902", "1903", ... , "1998", "1999" (soit 100 requêtes) dans un texte ou un CSV,
- on peut n'en faire qu'une :
19\d\dou mieux :19\d{2}
Rechercher des adresses emails :
- Au lieu de chercher des adresses emails dans un texte en ciblant les "@" puis en faisant une selection manuelle et un copier, coller,
- on peut toutes les trouver avec une seule reqûete :
[A-z\._-]+@[A-z\._-]+\.[A-z]
Elles sont aussi très utiles pour (re-)structurer rapidement un texte :
transformer un texte en fichier CSV
réagencer l'ordre des informations dans un document
normaliser des champs par lots. Exemple :
- Rechercher un nombre suivi de "fev", "fév", "février", "fevrier" :
(\d{,2}) (fév|fev|février|fevrier) - Remplacer par 02 suivi du nombre trouvé :
02-$1
- Rechercher un nombre suivi de "fev", "fév", "février", "fevrier" :
| Avant | | Après | | :--------- | :-: | :------- | | 28 février | → | 02-28 | | 9 fev | → | 02-9 | | 11 fév | → | 02-11 |
Les expressions régulières en bref¶
- une syntaxe :
[a-z](toutes les lettres de a à z en minuscule) ;?(0 ou 1 fois) ;+(1 ou plusieurs fois) ;*(0 ou plusieurs fois) ;{2,5}(entre 2 et 5 fois) ;[^a](pas un a) ;^a(un a au début d'une ligne) ; etc. ;()et$1(sélection pour rechercher/remplacer).
- des raccourcis (ou classes) :
\w(de A à Z, minuscule ou majuscule, et de 0 à 9 et_) ;\d(de 0 à 9) ;\s(caractères d'espacement),\n(saut à la ligne),\t(tabulation) ; etc.
- des caractères qui valent eux-mêmes :
a(un a) ;
- ou qu'il faut échapper :
\?(un point d'interrogation)
Les expressions régulières en action¶
➡️ https://www.musee-orsay.fr/fr/collections/arts-decoratifs
récupérer toutes les dates mentionnées dans la page
récupérer toutes les légendes d'images
➡️ Aide mémoire : https://regexr.com/
Quelques outils pour apprendre à utiliser les expressions régulières¶
- "Comprendre les expressions régulières" sur Programming Historian : https://programminghistorian.org/fr/lecons/comprendre-les-expressions-regulieres
- Regex Crossword : https://regexcrossword.com/
- Regex101 : https://regex101.com/
- Regexr : https://regexr.com/