

Objectifs du cours¶
🏆 Comprendre ce qu'est un document sur un ordinateur
🏆 Savoir différencier les catégories de fichiers et les standards et formats qui leur sont associés
🏆 Savoir différencier la mise en forme d'un fichier et sa structuration sémantique
🏆 Connaître théoriquement plusieurs modes d'organisation et de mise en forme d'un fichier textuel (XML, Markdown, LaTeX, ...)
🏆 Connaître théoriquement plusieurs modes de représentation de données organisées dans un fichier textuel (CSV, JSON)
🏆 Connaître les principaux standards XML et l'environnement technologique associé à ce standard
Plan du cours¶
- Acquisition de données textuelles
- Que faire avec des données textuelles
- Les expressions régulières
- Structuration des données
- XML
- TP : XML TEI
Acquisition de données textuelles¶
Quelques méthodes d'acquisition de données textuelles¶
saisie manuelle ou génération automatique de texte dans un document ;
récupération de données textuelles enregistrées dans une base de données ;
web scrapping ou extraction de contenus web ;
transcription d'un fichier multimédia par l'analyse et l'interprétation de son contenu ;
Du fichier multimédia au fichier texte¶
passe par l'analyse de signaux ou l'analyse des contenus
grâce à une approche symbolique fondée sur des règles
ou grâce à un apprentissage automatique (machine learning)
En fonction du contenu multimédia, il y a plusieurs domaines :
reconnaissance vocale automatique (
speech to text)reconnaissance automatique d'écriture (
optical character recognition)génération de texte décrivant le contenu (
automatic image/video/sound annotation)transformation du texte en un autre texte (
text simplification), ce qui s'apparente à de la traduction.
Des images au texte : la reconnaissance automatique de caractères¶
2 principaux champs d'application :
- écritures imprimées : peu voire pas de variation dans la forme des lettres (fonte) et chaque lettre est distincte des autres.

- écritures manuscrite : beaucoup de variations dans la forme des lettres, difficulté à dinstinguer certaines lettres, parfois des symboles (ou graphème) non standards.
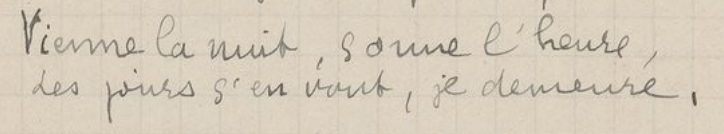
On parle d'OCR (Optical Character Recognition) ou d'HTR (Handwritten Text Recognition)
Etapes fondamentales de la transcription automatique¶
Acquisition des images (numérisation avec un cahier des charges adapté (cadrage, résolution, etc.)) ;
Pré-traitement des images (cadrage, réduction du bruit, parfois binarisation) ;
Détection du texte sur l'image (segmentation) ;
Détection de la mise en page (Layout Analysis) et de l'ordre des lignes ;
Reconnaissance du texte (lettre par lettre, mot par mot ou même phrase par phrase, en fonction du logiciel) ;
Post-taitement des données textuelles (correction des erreurs de transcription, annotation du texte, etc.).

Aller plus loin sur la gestion d'un projet de transcription automatique¶
📽️ Alix Chagué, "Comment faire lire des gribouillis à mon ordinateur ?", tuto@mate (11 mars 2021)
➡️ https://mate-shs.cnrs.fr/actions/tutomate/tuto31-lire-des-gribouillis-chague/
Dématérialisation et transcription automatique¶
Certaines campagnes de dématérialisation allient numérisation et transcription (automatique)
Une campagne de transcription peut être mise en place de plusieurs manières :
- avec un logiciel propriétaire et/ou payant (ex: FineReader d'ABBYY, Transkribus )
- avec un logiciel libre et ouvert (ex: Tesseract, eScriptorium )
- par le biais d'un prestataire, qui prend en charge le post-traitement (cf. liste de prestataires de numérisation )
- accompagnée de *crowdsourcing** pour le post-traitement (ex : Transcribe Bentham )
* Attention : le crowdsourcing peut sembler une solution facile, mais cela demande beaucoup d'organisation et une gros investissement.
Dématérialisation et transcription automatique¶
On ne devrait pas faire de transcription automatique sans cahier des charges :
- fixer les pratiques de transcription souhaitées
- fixer le seuil d'erreur minimal accepté
- expliciter les post-traitements nécessaires
- expliciter les formats d'enregistrement des données
Quelques logiciels de transcription supplémentaires¶
- Logiciels de transcription (imprimé et/ou manuscrit) :
- Tesseract
- CitLab (via Transkribus)
- Kraken
- FineReader
- OCRopus
- Plateformes gérant l'ensemble du workflow :
- OCR 4 all
- esCriptorium
- Transkribus
Que faire avec des données textuelles ?¶
Extraction d'informations¶
A l'aide de techniques de TAL (Traitement Automatique des langues / du langage) aussi appelé NLP (Natural Language Processing)
- Correction automatique
- Simplification/augmentation de texte
- Traduction automatique
- Extraction d'
entités nommées(NER, Named Entity Recognition) - Liage d'entités nommées (EL, Entity Linking) et désambiguation
- Analyses lexicométriques ou sémantiques
Faciliter l'accès¶
Rendre un document compatible avec des moteurs de recherche :
- moteur de recherche plein texte
- moteur de recherche combinant la recherche plein texte avec une recherche à facettes (via métadonnées)
- création d'index (de personnes, de lieux, etc) grâce aux entités nommées
Voire réaliser une édition numérique !
🕵️ Les expressions régulières désignent une syntaxe pour formuler des recherches (et des remplacements) dans un texte avec beaucoup de souplesse.
🕵️ On parle aussi de regex (regular expression) ou de recherche par motif.
🕵️ Elles sont en principe disponibles dans presque tous les éditeurs de texte, moyennant activation.
😔 Dans Microsoft Word les REGEX existent, mais depuis la version 2016, l'option s'appelle caractères génériques et la syntaxe diffère de la syntaxe universelle, même si le principe reste le même. ➡️ doc.

source: xkcd
Les REGEX facilitent la recherche de mots ou expressions que l'on appelle patterns (motifs)
Rercher des dates :
- Au lieu de chercher "1900", "1901", "1902", "1903", ... , "1998", "1999" (soit 100 requêtes) dans un texte ou un CSV,
- on peut n'en faire qu'une :
19\d{2}ou19\d\d
Rechercher des adresses emails :
- Au lieu de chercher des adresses emails dans un texte en ciblant les "@" puis en faisant une selection manuelle et un copier, coller,
- on peut toutes les trouver avec une seule reqûete :
[A-z\._-]+@[A-z\._-]+\.[A-z]
Elles permettent aussi de restructurer un texte (pour créer un CSV par exemple).
Elles supposent de regarder les données textuelles en détail pour identifier les repères qui peuvent aider à construire une bonne requêtes.
Les expressions régulières en action¶
➡️ https://www.musee-orsay.fr/fr/collections/arts-decoratifs
récupérer toutes les dates mentionnées dans la page
réucpérer toutes les légendes d'images
Quelques outils pour apprendre à utiliser les expressions régulières¶
- "Comprendre les expressions régulières" sur Programming Historian : https://programminghistorian.org/fr/lecons/comprendre-les-expressions-regulieres
- Regex Crossword : https://regexcrossword.com/
- Regex101 : https://regex101.com/
- Regexr : https://regexr.com/
Structuration des données¶
Pourquoi structurer les données¶
- trier les données afin qu'un utilisateur puisse facilement sélectionner celles qui sont importantes ;
- organiser les données pour les mettre en rapport les unes avec les autres ;
faire ressortir une structure logique qui aide à la mise en forme du document, à sa lecture par un humain ou par la machine ;
...
CSV (Comma Separated Values)¶
- 1 ligne de texte = 1 ligne de tableau
- 1 virgule = 1 nouvelle cellule de tableau
- un ficher csv peut être ouvert avec Excel
| Id_Monographie | Id_Enqueté | Serie_Tome | Prénom | Nom | Place dans la famille | Lieu de naissance |
|---|---|---|---|---|---|---|
| 001a | 001aE1 | 1-1 (1857) | Jean | M** | Père | T** (Aube) |
| 001a | 001aE2 | 1-1 (1857) | Marie | R** | Mère | L** (Meurthe) |
| 001a | 001aE3 | 1-1 (1857) | Joseph | M** | Fils |
Id_Monographie,Id_Enqueté,Serie_Tome,Prénom,Nom,Place dans la famille,Lieu de naissance
001a,001aE1,1-1 (1857),Jean,M**,Père,T** (Aube)
001a,001aE2,1-1 (1857),Marie,R**,Mère,L** (Meurthe)
001a,001aE3,1-1 (1857),Joseph,M**,Fils,,JSON (JavaScript Object Notation)¶
utilisation de structure similaire aux listes et aux dictionnaires en Python
Chaque valeur est associée à une étiquette, la structure peut fonctionner en arborescence, à plusieurs niveaux
[
{"Id_Monographie":"001a"}, {"Id_Enqueté":"001aE1"}, {"Serie_Tome":"1-1 (1857)"}, {"Prénom":"Jean"}, {"Nom":"M**"}, {"Place dans la famille":"Père"}, {"Lieu de naissance":"T** (Aube)"},
{"Id_Monographie":"001a"}, {"Id_Enqueté":"001aE2"}, {"Serie_Tome":"1-1 (1857)"}, {"Prénom":"Marie"}, {"Nom":"R**"}, {"Place dans la famille":"Mère"}, {"Lieu de naissance":"L** (Meurthe)"},
{"Id_Monographie":"001a"}, {"Id_Enqueté":"001aE3"}, {"Serie_Tome":"1-1 (1857)"}, {"Prénom":"Joseph"}, {"Nom":"M**"}, {"Place dans la famille":"Fils"}, {"Lieu de naissance":""}
]
Séparer la structure logique de l'apparence :¶
- un titre =/= un paragraphe
- un titre d'ouvrage ou un mot étranger
- une citation
vs.
- du texte en gras
- du texte en italique
- du texte entre guillemets
Séparer la structure logique de l'apparence :¶
En fonction du medium ou du contexte, on affiche un rendu particulier
toutes les mots en italiques ne sont pas des mots étrangers, mais tous les mots étrangers sont en italiques
on peut décider de finalement mettre les titres en gras tout en gardant les mots étrangers en italiques
on peut extraire rapidement tous les mots étrangers
Il extiste plusieurs conventions pour formaliser la structure logique.
Structuration logique dans un éditeur de texte¶
Dans Microsoft Word ou LibreOffice Writer :
- les styles pour gérer les titres et créer automatiquement une table des matières

WYSIWYM et WYSIWYG¶
dans un éditeur WYSIWYM : moindre confusion entre mise en forme et indication de la structure logique
la mise en forme apparaît après parsing du document (création d'un PDF ou ouverture dans un navigateur)
le paramétrage de la mise en forme peut être géré dans un fichier externe (ex: CSS pour HTML)
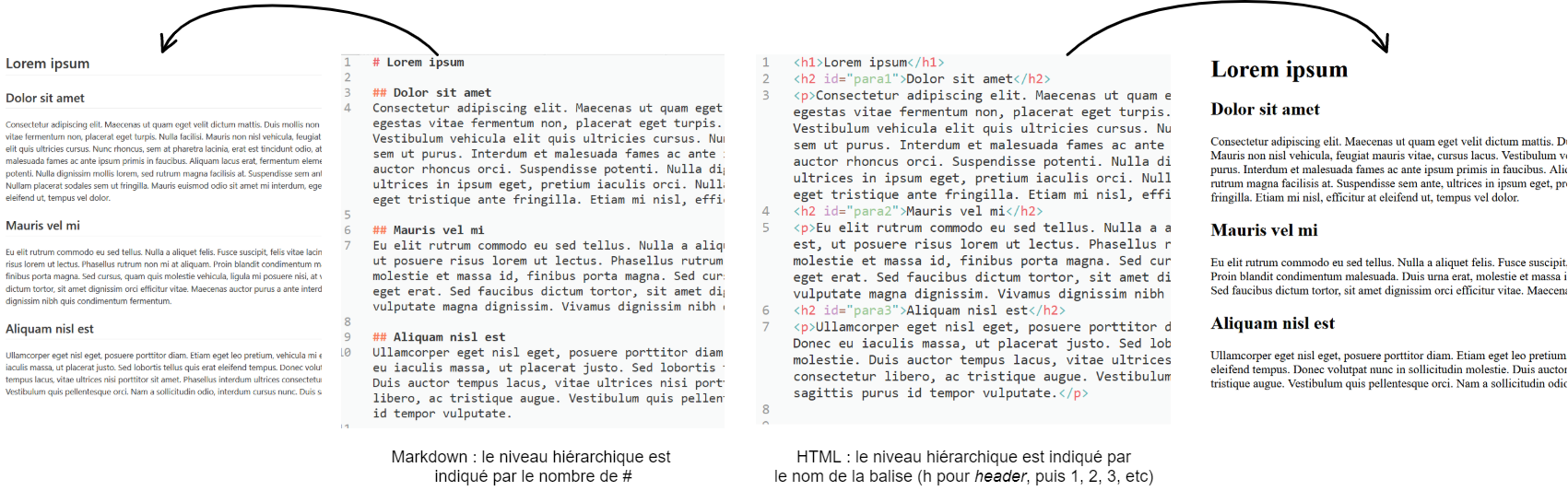
Annotation de la structure logique avec Markdown¶
Ⓜ️ Markdown est un langage de balisage léger qui permet d'encoder facilement la structure et certains éléments de mise en forme du texte sans gêner sa lecture.
Ⓜ️ Il permet de créer des fichiers HTML ou PDF et est beaucoup utilisé sur le web, notamment sur des plateformes comme Github
Ⓜ️ Même non compilé, un texte Markdown est facile à lire car les annotation sont légères et limitées ;
🤫 On peut utiliser Markdown ou un système similaire dans Whatsapp et Messenger ;
Markdown en exemple¶
Non compilé :
# Titre 1
##### Titre 5
[lien hypertexte](http://perdu.com/)
**texte mis en gras** (mise en forme)
~~texte barré~~ (mise en forme)Compilé :
Titre 1¶
Titre 5¶
lien hypertexte
texte mis en gras (mise en forme)
texte barré (mise en forme)
Structuration logique avec LaTeX¶
🇱 LaTeX (prononcer "latek") est un langage et un système de composition de documents, bien plus complet que Markdown ;
🇱 Il est très utilisé dans le domaine des sciences car il a été conçu pour écrire aisément les formules mathématiques ;
🇱 Un fichier annoté avec LaTeX est plus dur à lire sans compilation car les balises sont plus "invasives". Exemple : \chapter{Titre de chapitre}
🇱 Après compilation, on obtient un PDF ou du HTML
🇱 LaTeX ne sert pas qu'à annoter la structuration logique : il prend en charge la mise en forme du document au sens large.
XML permet de pousser beaucoup plus loin l'annotation sémantique¶

XML¶
{kind=link}
Qu'est-ce que XML ?¶
🌳 XML signifie eXtensible Markup Language
🌳 XML est un langage de balisage générique. On le dit extensible car il propose une grammaire générale pour l'organisation du document, mais on peut créer ses propres noms de balises
🌳 Comme HTML (Hypertext Markup Language), XML est un sous-ensemble du standard SGML (Standard Generalized Markup Language). Ces langages utilisent les chevrons (<>) pour former des balises.
🌳 XML définit une syntaxe :
- une balise XML est écrite entre chevrons (
< nom_de_la_balise >) et entoure généralement un contenu ; - une balise ouverte (
<slide>) doit donc être fermée (</slide>); - une balise peut-être vide :
<nothing></nothing>, ce qui peut aussi s'écrire :<nothing/> - un commentaire est écrit entre
<!-- ... -->;
XML : un exemple¶
<slide>
<titre>Qu'est-ce que XML ?</titre>
<para>
<line n="001">🌳 XML signifie <anglais>eXtensible Markup Language</anglais></line>
<line n="002">🌳 XML est un <gras>langage</gras> de <gras>balisage</gras> générique. On le dit <gras>extensible</gras> car il propose une grammaire générale pour l'organisation du document, mais on peut créer ses propres noms de balises</line>
</para>
</slide>
<slide>est une balise ou un élémentslideest un nom de balise- "Qu'est-ce que XML ?" est le contenu de la balise "titre"
nest un attribut de la balise "line"001est la valeur de l'attribut "n"
XML et les standards¶
🌳 XML ne définit pas de vocabulaire : il n'indique pas quel nom doit être donné à une balise : <paragraph>, <paragraphe>, <para>, <para_ph>, <p> sont tous des noms de balises valides ;
🌳 Ce sont les standards qui définissent un vocabulaire (un ensemble de nom de balise) et des règles de compositions :
XML TEI(Text Encoding Initiative) - description de documents textuels (1987)XML EAD(Encoded Archival Description) - description archivistique (1998)XML ALTO(Analysed Layout and Text Object) - description de la mise en page et du contenu d'un texte transcrit automatiquement (2004)XML SVG(Scalable Vector Graphics) - descriptions d'images vectorielles (1999)
Concepts et outils¶
🌳 Un fichier XML est plusieurs choses :
- un fichier de texte
- un arbre composé d'éléments hiérarchisés
- une base de données
🌳 Il existe plusieurs langages qui permettent d'interagir avec XML :
xPath: formuler un chemin à l'intérieur d'un arbre XML ;XSLT: transformer un arbre XML en un autre arbre XML ou en HTML ;xQuery: permet de faire des requêtes dans une base XML ;
Structure minimale obligatoire¶
<?xml version="1.0" encoding="UTF-8"?>
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>
<fileDesc>
<titleStmt>
<title>Title</title>
</titleStmt>
<publicationStmt>
<p>Publication Information</p>
</publicationStmt>
<sourceDesc>
<p>Information about the source</p>
</sourceDesc>
</fileDesc>
</teiHeader>
<text>
<body>
<p>Some text here.</p>
</body>
</text>
</TEI>
Qu'annoter ?¶
Métadonnées dans la balise
<teiHeader>Structure du texte (
<div>,<p>,<head>,<lb/>,<pb/>, ...)Entités ou informations spécifiques (
<date>,<placeName>, ...)Mise en forme (
<hi>, ...)Elements descriptifs (
<fw>, ...)
➡️ exemple : pont_mirabeau.xml
➡️ exemple : edition numérique de correspondances, projet DAHN