

Crédits¶
une partie du contenu de ces slides est librement inspirée des supports de cours de Johanna Daniel
une partie du contenu de ces slides est librement inspirée des supports de Laurent Romary, "A general introduction to the Text Encoding Initiative (TEI)"
Retrouver l'ensemble du cours sur 👉 github.com/alix-tz/EDL_typo_doc
Objectifs du cours¶
🏆 Comprendre ce qu'est un document sur un ordinateur
🏆 Savoir différencier les catégories de fichiers et les standards et formats qui leur sont associés
🏆 Savoir différencier "encodage" et "annotation"
🏆 Savoir différencier la mise en forme d'un fichier et sa structuration sémantique
🏆 Connaître théoriquement plusieurs modes d'organisation et de mise en forme d'un fichier textuel (XML, Markdown, LaTeX, ...)
🏆 Connaître théoriquement plusieurs modes de représentation de données organisées dans un fichier textuel (CSV, JSON)
🏆 Savoir comment acquérir et exploiter des données textuelles
🏆 Connaître les principaux standards XML et l'environnement technologique associé à ce standard
Plan du cours¶
- Acquisition de données textuelles
- Aparté sur les expressions régulières
- Structuration des données
- XML
- TP : XML TEI
Acquisition de données textuelles¶
Quelques méthodes d'acquisition de données textuelles¶
L'acquisition de données textuelles est opérée par plusieurs moyens, par exemple :
- saisie manuelle ou génération automatique de texte dans un document ;
- récupération de données textuelles enregistrées dans une base de données ;
- web scrapping ou extraction de contenus web ;
- transcription d'un fichier multimédia par l'analyse et l'interprétation de son contenu ;
Du fichier multimédia au fichier texte¶
Il s'agit d'utiliser des technologies d'interprétation des signaux contenus dans les fichiers multimédias (image, audio, ou même vidéo) pour interpréter la manière dont ils doivent être représentés dans un fichier texte.
Aujourd'hui, la plupart de ces techniques reposent sur de l'apprentissage automatique (ou machine learning).
Il peut s'agir de transcrire littéralement un contenu verbal écrit ou prononcé :
reconnaissance vocale automatique (
speech to text)reconnaissance automatique d'écriture (
optical character recognition)
Mais il peut aussi s'agir de générer un texte qui décrit le contenu d'une image, d'une vidéo, d'un extrait sonore (automatic image/video/sound annotation) ou encore d'un autre texte (text simplification).
Aparté sur l'apprentissage automatique : procédé¶
Prenons deux situations :
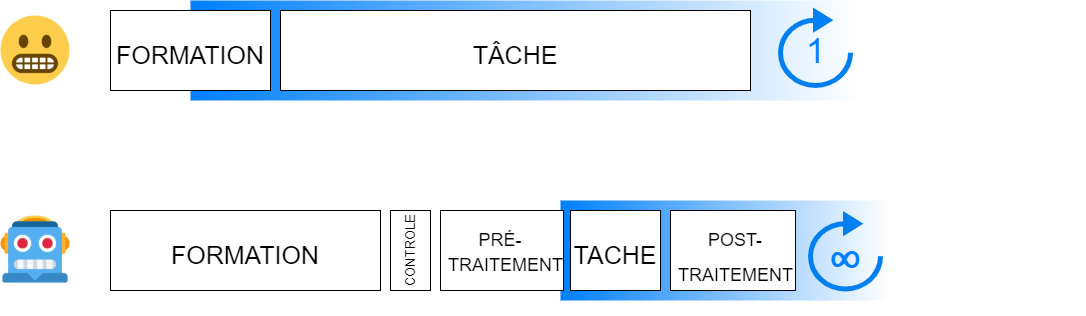
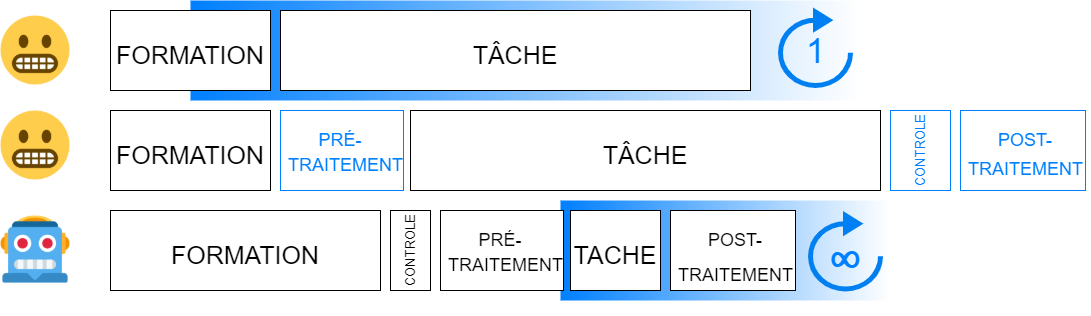
- On doit prendre en charge l'entraînement d'un modèle ex nihilo :
- Commencer par produire des exemples de résultats attendus : "données d'entraînement" ou "vérité-terrain" (ground truth) ;
- Puis entraîner un ou plusieurs modèles jusqu'à atteindre les performances voulues (taux d'erreur bas) ;
- il faut parfois augmenter la quantité de vérité-terrain ;
- il faut plusieurs allers-retours entre les entraînements et les données pour tester les modèles.
- Le logiciel utilisé dispose déjà de modèles adaptés aux données à traiter
- Vérifier que le modèle produit un résultat correspondant aux attentes (càd vérifier que les données ne sont pas trop spécifiques) ;
- Ne jamais s'attendre à un résultat parfait à 100% ;
- il faut parfois inclure une phase de traitement des données en amont (pré-traitement) ;
- il faut souvent ajouter une phase de correction des données obtenues (post-traitement).
Aparté sur l'apprentissage automatique : efficacité ?¶
En somme, utiliser des technologies d'apprentissage automatique, peut (en apparence) générer des tâches supplémentaires ou augmenter le temps passé à certaines tâches !
Mais cela permet de réduire le temps dédié à d'autres et rend possible le reprise d'une tâche depuis le début à moindre coût.
Aparté sur l'apprentissage automatique : efficacité ?¶
Et puis en réalité, ça ne fait que rendre plus visible certaines tâches qui existent déjà et auxquelles on fait moins attention habituellement.
Reconnaissance automatique d'écriture¶
Il existe deux grands domaines pour la reconnaissance d'écriture qui varient en fonction des types d'écritures :
- écritures imprimées : les caractères sont toujours formés de la même manière dans un texte donné (fonte) ou avec un minimum de variations.
- écritures manuscrites : la forme d'une lettre, d'un symbole ou d'un mot varie en fonction de sa place dans la page, dans la phrase, dans le mot, etc., mais aussi d'une personne à une autre. Pour ce domaine, on parle spécifiquement de "Handwritten Text Recognition", ou HTR.
Aujourd'hui, on obtient facilement une transcription automatique à partir de documents contenant des écritures imprimées (ex : nombreux services d'OCR en ligne), en revanche la transcription automatique des écritures manuscrites a encore beaucoup de progrès à faire.
Etapes fondamentales de la transcription automatique¶
Acquisition des images (numérisation avec un cahier des charges adapté (cadrage, résolution, etc.) ;
Pré-traitement des images (cadrage, réduction du bruit, parfois binarisation) ;
Détection du texte sur l'image (baselines) ;
Détection de la mise en page (Layout Analysis) et de l'ordre des lignes ;
Reconnaissance du texte (lettre par lettre, mot par mot ou même phrase par phrase, en fonction du logiciel) ;
Post-taitement des données textuelles (correction des erreurs de transcription, annotation du texte, etc.).

Dématérialisation et transcription automatique¶
Il est de plus en plus commun que les cahiers des charges guidant les campagnes de numérisations lancées par des institutions incluent une tâche de transcription automatique.
La transcription automatique peut être :
- réalisée à l'aide d'un logiciel propriétaire (exemple : FineReader d'ABBYY )
- réalisée à l'aide d'un logiciel libre et ouvert (exemple : Tesseract )
- réalisée par un prestataire qui prend en charge la correction des erreurs de transcription (exemple : liste de prestataires de numérisation )
- accompagnée d'une campagne de crowdsourcing* pour corriger les erreurs de transcription (exemple : Transcribe Bentham )
Dans tous les cas, il faut réfléchir en amont à l'usage que l'on souhaite associer aux documents numérisés et transcrits. De ces usages découle par exemple la qualité minimale acceptée pour la transcription.
* Attention : elle peut sembler une solution facile, mais ce n'est pas le cas !
Quelques logiciels de transcription¶
- Logiciels de transcription (imprimé et/ou manuscrit) :
- Tesseract
- CitLab (via Transkribus)
- Kraken
- FineReader
- OCRopus
- Plateformes gérant l'ensemble du workflow :
- OCR 4 all
- esCriptorium
- Transkribus
Que faire avec les données textuelles ?¶
📃 Il est possible d'appliquer plusieurs méthodes d'extraction d'informations sur des données textuelles.
📃 Lorsqu'elles sont automatisées grâce à des traitements informatiques, on parle de traitement automatique des langages (TAL) (ou NLP pour Natural Language Processing).
- correction automatique
- simplification/augmentation de texte
- traduction automatique
- extraction d'
entités nommées(ou NER pour Named Entity Recognition) - analyse sémantique à grande échelle
📃 Comme la phase de transcription automatique en est passée par une phase d'analyse de la mise en page, il est fréquent de conserver ces informations dans le document final :
- coordonnées de la portion de l'image correspondant au texte ;
- groupes de lignes formant un paragraphe, un titre, etc. ;
- autres éléments de mise en page spécifique (illustrations, tableau, etc.)
- parfois aussi information sur la mise en forme des caractères (gras, italique, taille, etc.)
Aparté sur les expressions régulières¶
🕵️ Les expressions régulières désignent une syntaxe pour formuler des recherches (et des remplacements) dans un texte avec beaucoup de souplesse.
🕵️ On parle aussi de regex (regular expression) ou de recherche par motif.
🕵️ Elles sont disponibles dans presque tous les éditeurs de texte, moyennant activation, mais certains logiciels les implémentent avec une syntaxe spécifique.
👿 par exemple : dans Microsoft Word , depuis la version 2016, l'option s'appelle caractères génériques et la syntaxe diffère de la syntaxe universelle, même si le principe reste le même. ➡️ doc.
🕵️ Avec les expressions régulières on peut:
chercher toutes les dates contenues dans un document étant donné, par exemple, qu'une date est une suite de 4 chiffres compris entre 1800 et 2020
chercher toutes les adresses mails contenues dans un document étant donné qu'une adresse mail contient des caractères alphanumériques, un
@et des.ou_ou-dans un certain ordre.et beaucoup plus encore !

source: xkcd
Les expressions régulières en bref¶
- une syntaxe :
[a-z](toutes les lettres de a à z en minuscule) ;?(0 ou 1 fois) ;+(1 ou plusieurs fois) ;*(0 ou plusieurs fois) ;{2,5}(entre 2 et 5 fois) ;[^a](pas un a) ;^a(un a au début d'une ligne) ; etc. ;()et$1(sélection pour rechercher/remplacer).
- des raccourcis (ou classes) :
\w(de A à Z, minuscule ou majuscule, et de 0 à 9 et_) ;\d(de 0 à 9) ;\s(caractères d'espacement),\n(saut à la ligne),\t(tabulation) ; etc.
- des caractères qui valent eux-mêmes :
a(un a) ;
- ou qu'il faut échapper :
\?(un point d'interrogation)
Les expressions régulières en action¶
- Exemple 1 : un motif pour chercher une date comprise entre 1000 et 2999 :
[1-2]\d{3}
- Exemple 2 : un motif pour chercher une adresse email :
[\w\.-]+@[\w\.-]+\.[\w]
- Exemple 3 : un motif pour trouver tous les liens URL dans un texte :
https?:\/\/[\w\.-]+
- pour démo :
Pourquoi apprendre et utiliser les expressions régulières ?¶
- certes, elles demandent un effort de modélisation des éléments textuels recherchés (ex : quelle structure trouve-t-on dans une adresse email et pas ailleurs ?)
- mais elles permettent de simplifier la recherche dans un texte (ex : pas besoin de faire 100 recherches pour trouver toutes les dates entre 1900 et 2000)
- elles permettent de supprimer ou modifier des portions de texte très ciblées en une seule fois (ex : inverser tous les jours et les mois dans une date exprimée selon le modèle MM-JJ-AAAA)
Quelques outils pour apprendre à utiliser les expressions régulières¶
- "Comprendre les expressions régulières" sur Programming Historian : https://programminghistorian.org/fr/lecons/comprendre-les-expressions-regulieres
- Regex Crossword : https://regexcrossword.com/
- Regex101 : https://regex101.com/
- Regexr : https://regexr.com/
Structuation des données¶
Structurer les données contenues dans un document permet (liste non exhaustive) :
- de trier les données afin qu'un utilisateur puisse facilement sélectionner celles qui sont importantes ;
- d'organiser les données pour les mettre en rapport les unes avec les autres ;
- de faire ressortir une structure logique qui aide à la mise en forme du document, à sa lecture par un humain ou par la machine ;
Organiser les données : CSV (Comma Separated Values)¶
- 1 ligne de texte = 1 ligne de tableau
- 1 virgule = 1 nouvelle cellule de tableau
- un ficher csv peut être ouvert avec Excel
| Id_Monographie | Id_Enqueté | Serie_Tome | Prénom | Nom | Place dans la famille | Lieu de naissance |
|---|---|---|---|---|---|---|
| 001a | 001aE1 | 1-1 (1857) | Jean | M** | chef de famille | T** (Aube) |
| 001a | 001aE2 | 1-1 (1857) | Marie | R** | sa femme | L** (Meurthe) |
| 001a | 001aE3 | 1-1 (1857) | Joseph | M** | leur fils |
Id_Monographie,Id_Enqueté,Serie_Tome,Prénom,Nom,Place dans la famille,Lieu de naissance
001a,001aE1,1-1 (1857),Jean,M**,chef de famille,T** (Aube)
001a,001aE2,1-1 (1857),Marie,R**,sa femme,L** (Meurthe)
001a,001aE3,1-1 (1857),Joseph,M**,leur fils,,Organiser les données : JSON (JavaScript Object Notation)¶
utilisation de structure similaire aux listes et aux dictionnaires en Python
Chaque valeur est associée à une étiquette, la structure peut fonctionner en arborescence, à plusieurs niveaux
[
{"Id_Monographie":"001a"}, {"Id_Enqueté":"001aE1"}, {"Serie_Tome":"1-1 (1857)"}, {"Prénom":"Jean"}, {"Nom":"M**"}, {"Place dans la famille":"chef de famille"}, {"Lieu de naissance":"T** (Aube)"},
{"Id_Monographie":"001a"}, {"Id_Enqueté":"001aE2"}, {"Serie_Tome":"1-1 (1857)"}, {"Prénom":"Marie"}, {"Nom":"R**"}, {"Place dans la famille":"sa femme"}, {"Lieu de naissance":"L** (Meurthe)"},
{"Id_Monographie":"001a"}, {"Id_Enqueté":"001aE3"}, {"Serie_Tome":"1-1 (1857)"}, {"Prénom":"Joseph"}, {"Nom":"M**"}, {"Place dans la famille":"leur fils"}, {"Lieu de naissance":""}
]
Structuration logique¶
📑 La mise en forme des données textuelles permet de faire apparaître la structure logique d'un document :
- en gras et dans une police plus grande on mettra les titres ;
- en italique on mettra les titres d'ouvrages ou les mots étrangers ;
- entre guillemets on mettra les citations ;
- etc.
📑 Mais la mise en forme varie d'un médium, d'un contexte à l'autre et sa signification peut être ambiguë :
- on peut donc indiquer la structure logique sous la forme d'annotations associées à des portions de texte
- cela permet de modifier rapidement la mise en forme associée à tel ou tel élément logique en fonction du contexte éditorial
- il existe plusieurs conventions pour formuler ces annotations
Structuration logique dans un éditeur de texte¶
- Dans
Microsoft Wordou son équivalent libreLibreOffice Writer, on utilise les (malnommés)Stylespour rendre compte de la structure logique d'un document (cela permet de générer ensuite une table des matières, par exemple)

Titres, hiérarchie et paragraphes¶
Lorsqu'on annote la structure logique dans un éditeur WYSIWYM, la confusion entre mise en forme et indication de la structure logique est moindre.
La mise en forme est opérée au moment du parsing du document (ouverture dans un navigateur par exemple), un fichier externe peut indiquer les règles de mise en forme (ex : CSS pour HTML).
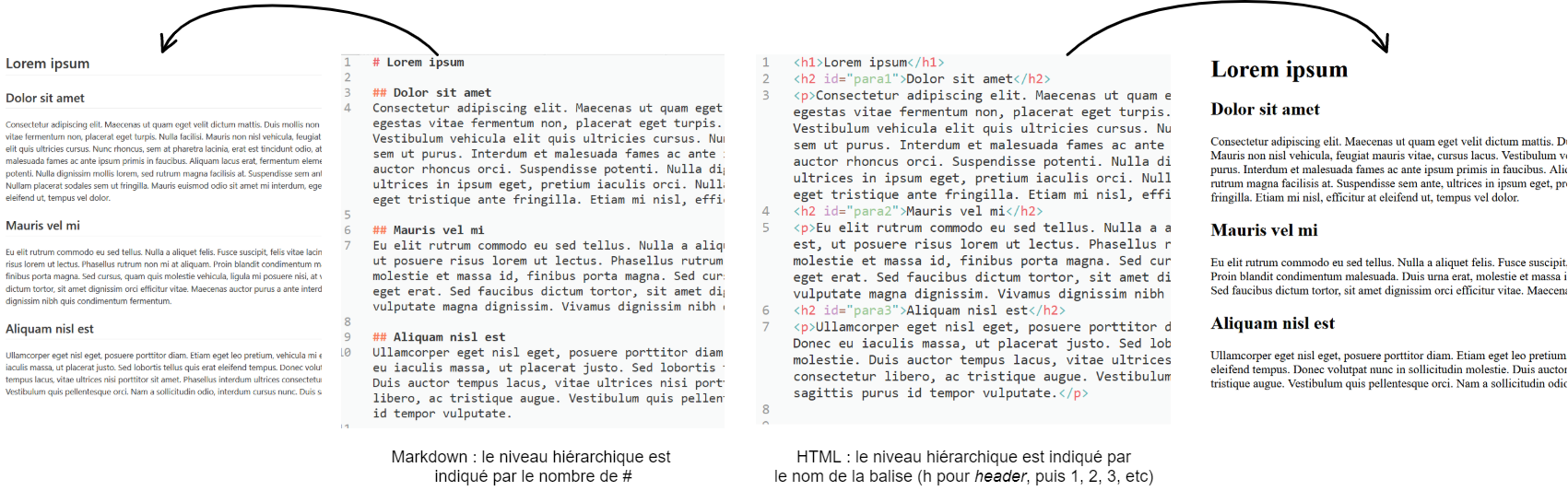
Annotation de la structure logique avec Markdown¶
Ⓜ️ Markdown est un langage de balisage léger qui permet d'encoder facilement la structure et certains éléments de mise en forme du texte sans gêner sa lecture. Il a été créé en 2004 par John Gruber et Aaron Swartz (US) ;
Ⓜ️ Après compilation, on obtient un fichier HTML ou un PDF. Markdown permet donc de créer rapidement des contenus web ou des documents qui restent faciles à lire qu'ils soient compilés ou non ;
Ⓜ️ Pour rester simples à lire, les annotations de Markdown sont très légères et limitées ;
🤫 On peut utiliser Markdown ou un système d'annotation similaire dans Whatsapp et Messenger ;
Markdown en exemple¶
Non compilé :
# Titre 1
##### Titre 5
[lien hypertexte](http://perdu.com/)
**texte mis en gras** (mise en forme)
~~texte barré~~ (mise en forme)Compilé :
Titre 1¶
Titre 5¶
lien hypertexte
texte mis en gras (mise en forme)
texte barré (mise en forme)
Structuration logique avec LaTeX¶
🇱 LaTeX (prononcer "latek") est un langage et un système de composition de documents, bien plus complet que Markdown ;
🇱 Il a été élaboré en 1985 par Leslie Lamport à partir d'un autre langage plus ancien : TeX ;
🇱 Il est très utilisé dans le domaine des sciences car il a été conçu pour écrire aisément les formules mathématiques ;
🇱 Un fichier annoté avec LaTeX est plus dur à lire sans compilation car les balises sont plus "invasives". Exemple : \chapter{Titre de chapitre}
🇱 Après compilation, on obtient généralement un fichier PDF, mais il est aussi possible de transformer le texte avant compilation pour créer un fichier HTML, etc.
🇱 LaTeX ne sert pas qu'à annoter la structuration logique : il prend en charge la mise en forme du document au sens large.
Pour la structuration des données textuelles, il y a encore plus puissant¶

XML¶
Qu'est-ce que XML ?¶
🌳 XML signifie eXtensible Markup Language
🌳 XML est un langage de balisage générique. On le dit extensible car il propose une grammaire générale pour l'organisation du document, mais on peut créer ses propres noms de balises
🌳 Comme HTML (Hypertext Markup Language), XML est un sous-ensemble du standard SGML (Standard Generalized Markup Language). Ces langages utilisent les chevrons (<>) pour former des balises.
🌳 XML définit une syntaxe :
- une balise XML est écrite entre chevrons (
< nom_de_la_balise >) et entoure généralement un contenu ; - une balise ouverte (
<slide>) doit donc être fermée (</slide>); - une balise peut-être vide :
<nothing></nothing>, ce qui peut aussi s'écrire :<nothing/> - un commentaire est écrit entre
<!-- ... -->;
XML : un exemple¶
<slide>est une balise ou un élémentslideest un nom de balise- "Qu'est-ce que XML ?" est le contenu de la balise "titre"
nest un attribut de la balise "line"001est la valeur de l'attribut "n"
<slide>
<titre>Qu'est-ce que XML ?</titre>
<para>
<line n="001">🌳 XML signifie <anglais>eXtensible Markup Language</anglais></line>
<line n="002">🌳 XML est un <gras>langage</gras> de <gras>balisage</gras> générique. On le dit <gras>extensible</gras> car il propose une grammaire générale pour l'organisation du document, mais on peut créer ses propres noms de balises</line>
</para>
</slide>
XML et les standards¶
🌳 XML ne définit pas de vocabulaire : il n'indique pas quel nom doit être donné à une balise : <paragraph>, <paragraphe>, <para>, <para_ph>, <p> sont tous des noms de balises valides ;
🌳 Ce sont les standards qui définissent un vocabulaire (un ensemble de nom de balise) et des règles de compositions :
XML TEI(Text Encoding Initiative) - description de documents textuels (1987)XML EAD(Encoded Archival Description) - description archivistique (1998)XML ALTO(Analysed Layout and Text Object) - description de la mise en page et du contenu d'un texte transcrit automatiquement (2004)XML SVG(Scalable Vector Graphics) - descriptions d'images vectorielles (1999)
Concepts et outils¶
🌳 Un fichier XML est plusieurs choses :
- un fichier de texte
- un arbre composé d'éléments hiérarchisés
- une base de données
🌳 Il existe plusieurs langages qui permettent d'interagir avec XML :
xPath: formuler un chemin à l'intérieur d'un arbre XML ;XSLT: transformer un arbre XML en un autre arbre XML ou en HTML ;xQuery: permet de faire des requêtes dans une base XML ;
TP : XML TEI¶
Ressources pour le TP¶
Structure minimale obligatoire¶
<?xml version="1.0" encoding="UTF-8"?>
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>
<fileDesc>
<titleStmt>
<title>Title</title>
</titleStmt>
<publicationStmt>
<p>Publication Information</p>
</publicationStmt>
<sourceDesc>
<p>Information about the source</p>
</sourceDesc>
</fileDesc>
</teiHeader>
<text>
<body>
<p>Some text here.</p>
</body>
</text>
</TEI>
Qu'annoter ?¶
Métadonnées dans la balise
<teiHeader>Structure du texte (
<div>,<p>,<head>,<lb/>,<pb/>, ...)Entités ou informations spécifiques (
<date>,<placeName>, ...)Mise en forme (
<hi>, ...)Elements descriptifs (
<fw>, ...)
➡️ exemple : https://raw.githubusercontent.com/alix-tz/EDL_typo_doc/main/tp/transcription_M5050_X0031_FGM_LEG_1_001_P.xml