022 - McCATMuS #5 - Training models
Last week, I visited Rimouski in the Bas-Saint-Laurent region of Québec, along the South-eastern bank of the St Laurent river. I was invited to contribute to discussions around the Nouvelle-France Numérique project, and I took this opportunity to present HTR-United, CATMuS as well as preliminary results on training a McCATMuS model. In preparation for this presentation, I conducted a series of tests on the two first models I trained. Today, this blog post gives me a space to discuss these tests and their results in more details.
The Kraken McCATMuS models were not directly trained on the HuggingFace dataset I introduced in my previous post, but rather on ARROW files created with the same ALTO XML files used to create the HuggingFace dataset. At the beginning of September, I wrote a Python script which reproduces the split of ALTO XML files into the train, validation and test sets, and which applies the same type of filtering of lines and modifications as I previously presented. Instead of generating the PARQUET files for HuggingFace, it simply creates alternative .catmus_arrow.xml files and three listings of these files, ready to be served to a ketos compile command1.
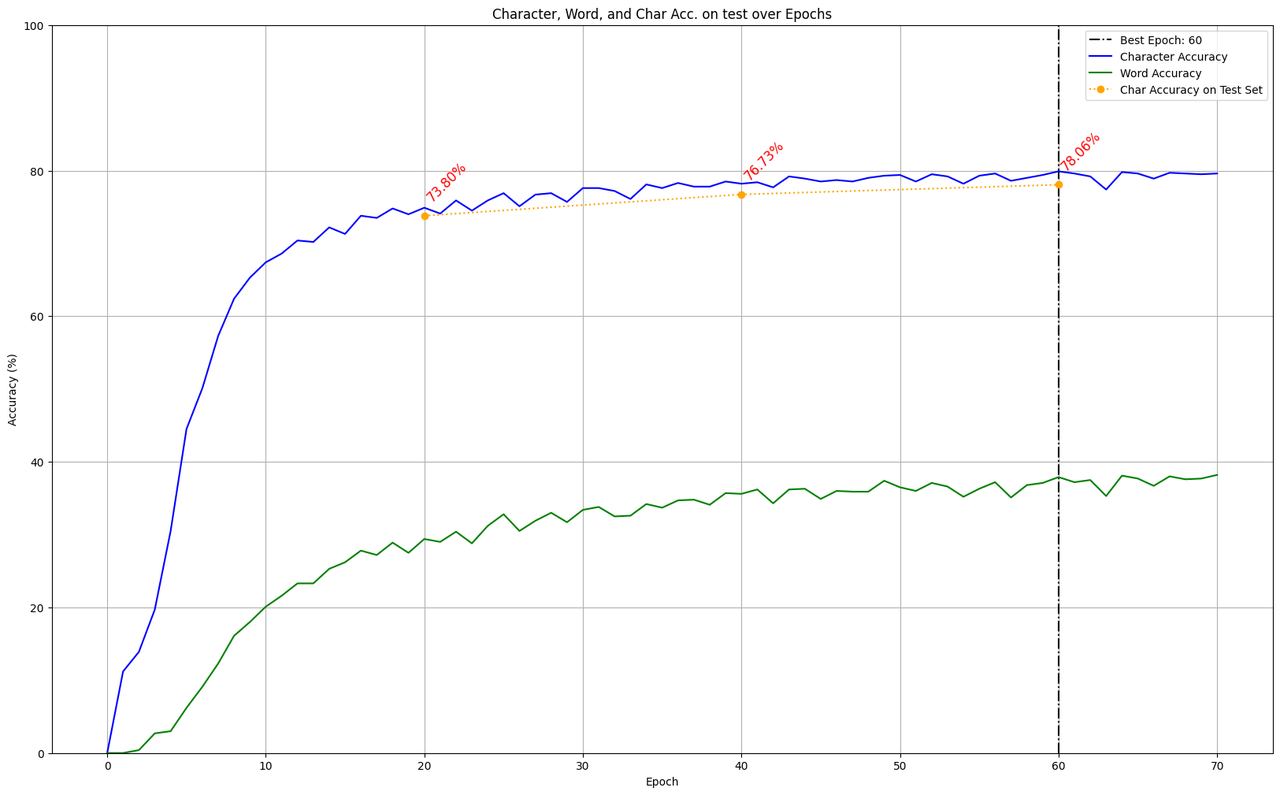
I used Kraken 4.3.13 to train the models on Inria's computation server because I've had dependency issues with Kraken 5 and haven't fixed them yet. The first model I trained strictly followed the train/validation split thanks to the --fixed-splits option. After 60 epochs, the model plateaued at 79.9% of character accuracy. When applied to the test set, this accuracy remained at 78.06%, a mere two points drop.
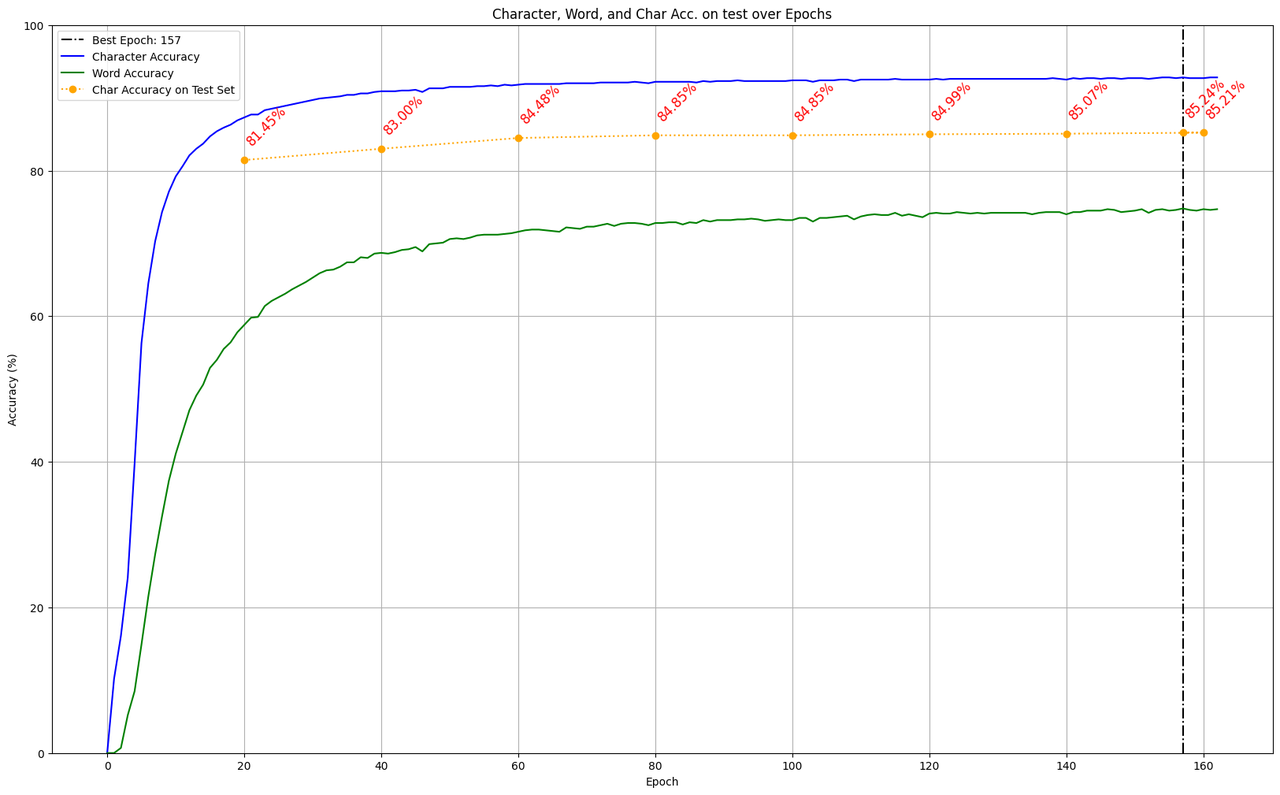
I trained a second model using the same parameters2 but without the --fixed-splits option, allowing Kraken to shuffle the train set and the validation set into a 90/10 split (the test set was left untouched however). This time, the training lasted 157 epochs before stopping, with the best model scoring with an accuracy of 92.8% on the validation set. When applied to the test set however, the model lost 7 points of accuracy (85.24%).
Although disappointing, this was consistent with the observations made when training the CATMuS Medieval model:
As anticipated, the "General" split exhibits lower CER, given the absence of out-of-domain documents, whereas the "Feature"-based split surpasses 10%. This higher score presents an intriguing challenge for developing more domain-specific models that consider factors such as script type and language. (from Thibault Clérice, Ariane Pinche, Malamatenia Vlachou-Efstathiou, Alix Chagué, Jean-Baptiste Camps, et al.. CATMuS Medieval: A multilingual large-scale cross-century dataset in Latin script for handwritten text recognition and beyond. 2024 International Conference on Document Analysis and Recognition (ICDAR), 2024, Athens, Greece. ⟨hal-04453952⟩ p. 15)
So, the drop in accuracy observed on the test set is, as suggested in Clérice et al, 2024, likely due to the fact that with a fixed-split, the model is both validated and tested against out-of-domain hands and documents (although the documents differ in the two sets). On the other hand, the model trained with a random split is validated against known hands and documents, but tested on out-of-domain examples.
The test set contains transcriptions of printed, typewritten and handwritten texts, covering all centuries. Limiting ourselves to only one accuracy score obtained on the whole test set would tell us very little about the model's capacity and its limitations. This is why I divided the test set into several smaller test sets based on the century of the documents and/or on the main type of writing present in the documents. For documents spanning over several centuries, I used the most represented century.
I only used the McCATMuS trained on the random split for these tests, because the accuracy of the other one was too low for the results to be meaningful. Instead of only testing McCATMuS, I also ran the Manu McFrench V3 and McFondue on the McCATMuS test set. They are two generic models trained on similar data (although with no or different normalization approaches).
| Test set.............. | ...McCATMuS... | ...Manu McFrench V3... | ...McFondue |
|---|---|---|---|
| All................... | ...85.24... | ...91.17... | ...76.12 |
| Handwritten........... | ...78.72... | ...89.40... | ...75.17 |
| Print................. | ...96.37... | ...94.15... | ...78.30 |
| Typewritten........... | ...90.93... | ...92.69... | ...58.13 |
| 17th cent............. | ...87.27... | ...86.39... | ...72.81 |
| 18th cent............. | ...88.65... | ...94.21... | ...81.64 |
| 19th cent............. | ...79.81... | ...93.70... | ...75.46 |
| 20th cent............. | ...74.92... | ...86.52... | ...56.74 |
| 21st cent............. | ...73.86... | ...90.20... | ...68.04 |
| (HW) 17th cent........ | ...58.69... | ...64.83... | ...64.26 |
| (HW) 18th cent........ | ...85.38... | ...93.35... | ...80.47 |
| (HW) 19th cent........ | ...79.81... | ...93.70... | ...75.46 |
| (HW) 20th cent........ | ...63.02... | ...82.23... | ...55.89 |
| (HW) 21st cent........ | ...73.86... | ...90.20... | ...68.04 |
I was initially surprised by the consistent margin Manu McFrench had over McCATMuS, considering it was trained on less data (73.9K + 8.8K lines, against the 106K + 5.8K lines) which had not been harmonized to follow the same transcription rules. However, these scores are actually biased in favor of Manu McFrench because several of the documents included in the McCATMuS test set were also used in Manu McFrench's train set. Even though this is not true for all documents, it concerns almost half of the test set. It might also be the case for McFonddue, but this model scores higher than McCATMuS in only one instance (handwritten documents from the 17th century). Creating a new test set, with documents that are not present in any of the train sets but follow the CATMuS guidelines, would be a good way to confirm this bias.
Additionally, I detected an issue in one of the datasets used in the test set: FoNDUE_Wolfflin_Fotosammlung contains some lines of faulty transcriptions, resulting from automatic text recognition, which most certainly cause an inaccurate evaluation of all three models.
A couple of examples of the faulty transcriptions, along with their CER they generate when compared to what would be a correct transcription (the CER is generated with CERberus):
Line image Faulty transcription Correct transcription Faulty CER would be "CSTITHER, KIESERMAEAER AogS." "COLLECTION HANFSTAENGL LONDON" 89.29 "PEcLioL." "NATIONAL GALLERY" 175.0

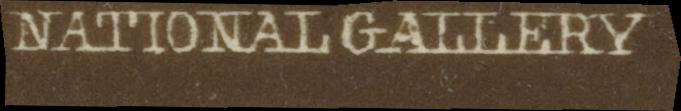
I have planned to manually control this dataset and update the McCATMuS dataset accordingly. I don't know yet how many lines are affected.
The better accuracy of the Manu McFrench model is not just a product of the biases in the test set. I had the occasion to apply it to two documents, one from the 17th century and one from the 20th century. In both cases, Manu McFrench's transcription seemed more likely to be correct than McCATMuS's. This has led me to compare the training parameters used for both models and to start a third training experiment using Manu McFrench's parameters. In this case, the batch size is reduced to 16 (as opposed to 32) and the Unicode normalization follows NFKD instead of NFD.
If the results of this third training are consistent with the previous experiments, it will be interesting to see if adding more data to the training set will improve the results. Also, I have yet to test the model in a situation of finetuning.
As said at the beginning of this post, these results are preliminary, so I hope to have more to share in the coming weeks.
-
The command looks like this: cat "./list_of_paths.txt" | xargs -d "\n" ketos compile -o "./binary_dataset.arrow" --random-split .0 .0 1.0 -f alto. ↩
-
The configuration of Kraken for training these two model relies on the default network architecture, on a NFD Unicode normalization, a learning rate of 0.0001 (1e-4), batch size of 32, padding of 16 (default value), and applies augmentation (
--augment). The--fixed-splitsoption is used for the first model. Following Kraken's default behavior, the training stops when the validation loss does not decrease for 10 epochs (early stops); this prevents the model from overfitting, which is confirmed when looking at the accuracy score of the intermediary models on the test set (orange line on the graphs). The training is done on a GPU. ↩